I Built an AI Second Brain That Versions Itself. Here's Why Markdown Files Won't Get You There.
After building two AI-powered products and running hundreds of AI coding sessions, almost none of the knowledge persisted. That pain led to Knowledge Packs — versioned, typed, auto-generated intelligence that makes every session smarter than the last.
I've been building two AI-powered products in parallel — Jivant, a health data organizer for Indian families (200K+ lines of Swift, hundreds of AI coding sessions), and 2Pizza, an AI agent that audits how accurately AI represents local businesses. Two completely different domains, two different tech stacks, hundreds of sessions between them. The knowledge generated across both was enormous. The knowledge that persisted? Almost zero.
I couldn't find the architectural decision I made last Tuesday. Patterns I discovered debugging Jivant's CoreData layer never transferred to 2Pizza's crawl pipeline. I had a 2,000-line CLAUDE.md for Jivant. Every time I discovered a pattern or made an architectural decision, I'd manually add it. Every time an anti-pattern bit me twice, I'd write a rule.
It worked — until it didn't.
The problem isn't capture. The problem is maintenance. My CLAUDE.md grew stale within days of any section I stopped actively editing. Rules I wrote in January referenced architecture that changed in March. Patterns I documented for React 18 became irrelevant when I migrated a module to SwiftUI. The file was 2,000 lines, but maybe 400 were still accurate.
I expected the hard part to be getting information into the second brain. The actual hard part is keeping it alive. So I built one that maintains itself.
The Missing Layer in the AI Stack
The AI tooling stack has evolved fast. Anthropic's Model Context Protocol (MCP) gave agents access to your tools. Agents got autonomous. Skills made them repeatable. But there's a layer missing — and it's the one that makes all of it compound.
Your AI doesn't remember what it learned yesterday. It can execute complex workflows, call APIs, run tests, deploy code. But ask it about the architectural decision you made last week? It has no idea. Every session starts from zero.
MCP, agents, and skills give your AI capabilities. What's missing is the knowledge layer — living, breathing intelligence that grows with every session and injects itself back into the next one. That's what Knowledge Packs are.
Then Karpathy Said the Same Thing
Weeks after I had a working system, Andrej Karpathy dropped a video about building a “second brain” for LLMs. Within 48 hours, my X bookmarks filled with builders sharing their versions: markdown vaults, CLI scripts, prompt chains, elaborate folder structures. Builders across the AI-tools space were converging on the same problem I'd already been solving.
Here's the honest landscape of what's being built.
The manual curators. Karpathy's own approach is copy-paste into structured markdown. It works for one person with discipline, but it doesn't scale past a few hundred entries before maintenance burden exceeds capture value.
The vault architects. Nick Spisak's “Second Brain for AI” framework is more sophisticated. He defines four operations — Onboard, Ingest, Query, Lint — and argues for dedicated domain-specific vaults rather than one general-purpose knowledge base. The architecture is sound, but the execution is still manual. You're the one deciding what goes in, structuring it, and keeping it current.
The graph generators. Graphly auto-generates knowledge graphs from AI conversations, discovering relationships that flat documents miss. This is genuinely powerful — it finds connections you didn't know existed. But it's read-only intelligence. The graph doesn't feed back into your next session automatically.
The filesystem integrators. MCP-based “docs-as-filesystem” tools give AI agents real-time access to your Google Docs, Notion, and local files. This solves the input problem — the AI can read your existing context. But it doesn't solve the output problem — distilling what the AI learned back into persistent, structured knowledge.
Every approach I found falls into one of two traps:
Trap 2: Raw retrieval. Feeds everything to the AI via RAG or filesystem access. Solves the “AI can see my stuff” problem but creates context pollution — the model spends 2,000 tokens reading your Google Doc when it needed 50 tokens of the three relevant decisions.
What nobody has built is the infrastructure layer: automatic extraction, structured typing, version control, token-budgeted injection, and a closed feedback loop.
The Architecture That Actually Works
Here's what I built instead, and — more importantly — why each piece matters.
Automatic extraction, not manual curation
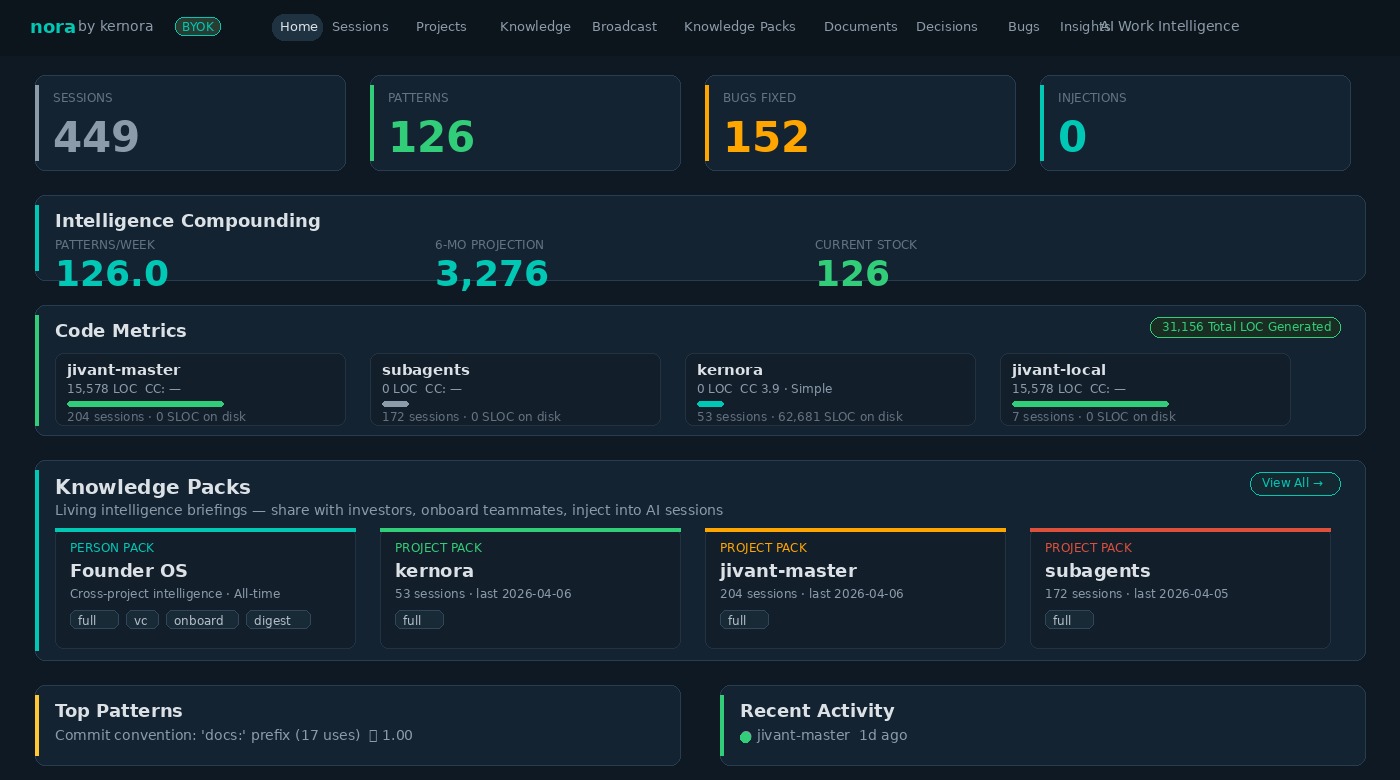
Every AI coding session I run generates a JSONL transcript. Nora, the analysis engine inside Kernora, processes these transcripts and automatically extracts structured intelligence: patterns with effectiveness scores, anti-patterns with context, architectural decisions with rationale, process documentation, and technology associations. I didn't type any of this. The system extracted it from 200+ sessions across five projects.
Typed intelligence, not flat chunks
This is where most second brain approaches fail. They store knowledge as text — paragraphs, bullet points, markdown sections. All knowledge looks the same.
Nora categorizes extracted intelligence into typed sections: patterns (things that work), anti-patterns (things that break), decisions (architectural choices with rationale), processes (repeatable workflows), learnings (one-time insights), and tenets (principles that guide decisions).
Why does typing matter? Because the AI doesn't need all knowledge equally. When it's about to refactor a module, it needs anti-patterns and decisions. When it's onboarding to a new project, it needs processes and tech stack. When it's debugging, it needs patterns and known bugs. Typed knowledge makes selective loading possible.
Token-budgeted injection
Every Knowledge Pack generates a pre-rendered injection_md block — exactly 500 tokens of the highest-signal intelligence for that project. Top 5 rules, 3 critical anti-patterns, 3 active decisions. This block auto-injects into every AI session via the project's CLAUDE.md file. Zero latency, zero vector search, zero retrieval cost.
For deeper context, the full pack (2,000–5,000 tokens) loads on demand via an MCP tool call. But the 500-token injection handles 80% of cases. This is the key insight: context isn't free. Every token of context you inject displaces a token of reasoning. A 500-token injection that's 90% signal beats a 5,000-token RAG retrieval that's 20% signal.
Semver versioning with diff tracking
Each Knowledge Pack carries a semantic version — 1.0.0, 1.1.0, 2.0.0. When the system detects changes after a new session analysis, it auto-bumps the version: PATCH for new patterns added, MINOR for new sections, MAJOR for scope changes. Every version gets a diff summary: “+3 patterns, -1 decision, ~2 learnings updated.”
Why version knowledge? The same reason you version code: auditability, rollback, and drift detection. When my Jivant Knowledge Pack went from 1.0.0 to 1.4.2 over three months, I could trace exactly how the project's intelligence evolved.
The closed flywheel
This is the piece that makes everything compound:
↓
CLAUDE.md Injection → Better AI Session → Repeat
Every session makes the next session smarter, automatically. I didn't have to curate anything. I didn't have to update a markdown file. I ran my normal AI coding sessions, and the system extracted the intelligence, versioned it, and injected it back. After 200+ sessions, the compounding is unmistakable.
The Six Knowledge Pack Types
Nick Spisak was right about one thing: you need multiple, domain-specific knowledge bases, not one monolithic vault. I landed on six types:
Project Packs contain everything the AI needs to work on a specific codebase — Jivant's patterns, Kernora's architecture decisions, Vidafolio's tech stack. Auto-generated after every session analysis. This is the workhorse.
Person Packs aggregate cross-project intelligence about a specific person. My “Mihir Founder OS” pack knows my working style, technology preferences, product tenets, and recurring decision patterns across all five projects. It's what makes a brand-new AI session feel like talking to someone who already knows me.
Domain Packs capture expertise in a technology area — React 18, iOS SwiftUI, PostgreSQL optimization. Curated, not auto-generated, and the ones I see becoming shareable across teams.
Playbook Packs document business processes — fundraising, sales, hiring, product launches. Partially auto-generated from session intelligence about those activities.
Onboard Packs are a filtered view of project intelligence, scoped to the last 90 days. For new team members or contractors who need current context without historical noise.
Digest Packs are weekly summaries across all projects — this week's decisions, new patterns, open bugs. My Sunday evening review ritual.
The key insight: each type serves a different consumer at a different moment. Same underlying intelligence, different packaging for different work surfaces.
The Honest Gaps
I'm not going to pretend this system is complete. Here's what I haven't solved yet.
External intelligence ingest. Right now, Knowledge Packs are built entirely from AI session transcripts. They don't pull from Google Docs, Notion, Slack, or email. The session-only view misses strategic context that lives in documents.
Real-time graph generation. Graphly's automatic knowledge graph discovery is genuinely powerful. My typed, structured approach is better for injection and versioning, but worse at discovering implicit relationships between concepts. A hybrid would be ideal.
Code-level pattern extraction. Today, Nora extracts patterns from conversation text. It doesn't analyze the actual code AST for architectural patterns. Tree-sitter integration would let the system detect patterns like “this codebase always uses repository pattern for data access” without anyone saying it explicitly.
Pack composition and inheritance. When I work on Kernora's iOS native app, I need both the Kernora Project Pack and the iOS SwiftUI Domain Pack loaded. A composition layer that merges relevant packs with de-duplication would reduce total token cost.
These gaps matter. But the automation flywheel — the part where knowledge compounds without human intervention — is working now, and that's the piece nobody else has.
The Part Nobody Talks About
The emotional shift is the real story.
For fifteen years as an engineering leader, I accumulated institutional knowledge the old-fashioned way: in my head, in scattered docs, in tribal knowledge shared over coffee. When I left each company, most of that knowledge walked out the door with me. When new engineers joined, we'd spend weeks downloading context that should have been available on day one.
Building this system, I experienced something I didn't expect: relief. Not from the automation — from the acknowledgment that knowledge is an asset worth managing.
Every engineering organization treats code as a first-class asset. We version it, test it, review it, deploy it through controlled pipelines. But the knowledge that informs code — the decisions behind the architecture, the patterns that prevent bugs, the anti-patterns that save debugging hours — we treat as ephemeral. “It's in someone's head.” “Check the Confluence page from 2023.” “Ask Sarah, she built that module.”
What if we treated engineering knowledge with the same rigor as engineering code? Version it. Type it. Test it for staleness. Inject it automatically where it's needed.
That's not a tool feature. That's a category shift.
What You Can Steal
You don't need to build what I built. But here are five patterns you can apply Monday morning:
Type your knowledge. Stop putting everything in one flat file. Separate patterns (things that work), anti-patterns (things that break), decisions (choices with rationale), and processes (repeatable steps). Even manual categorization makes AI interactions dramatically better.
Budget your tokens. If your CLAUDE.md is over 500 tokens, you're probably injecting noise. Distill it to the top 5 rules, 3 anti-patterns, and 3 active decisions. Load everything else on demand.
Version your context files. Put your CLAUDE.md under git version control. Track when rules change. Review the diff monthly. You'll be surprised how much drifts.
Close the feedback loop. After every significant AI session, spend 60 seconds asking: “What did I learn that should persist?” Then add it to the appropriate typed section. This is the manual version of the flywheel, and it still compounds.
Think in packs, not pages. Group knowledge by consumer and moment: what does the AI need at session start? What does a new team member need on day one? What do I need for my weekly review? Same knowledge, different slices.
The second brain movement is real. The infrastructure to support it barely exists. The opportunity — for builders, for teams, for the next generation of AI-native tools — is to close the gap between “everyone agrees this is important” and “it actually works without constant maintenance.”
Give your AI a memory that compounds
Nora captures sessions, extracts verified patterns, and injects them back. Every session sharpens the next.
curl -fsSL https://kernora.ai/install | bash
The analysis engine behind all of this is Nora — open source at github.com/kernora-ai/nora. It runs locally, uses your own API key, and stores everything in SQLite on your machine. Zero telemetry. If you're using Claude Code or Kiro, you can install it in 30 seconds and start accumulating intelligence from your next session.
Mihir Choudhary — serial entrepreneur, founder at Kernora. Previously SVP leading engineering teams at scale. Now building AI work intelligence that compounds. If you're thinking about building your own AI second brain, start with the typing system, not the capture mechanism. The structure is what makes it useful.